
音声を収録・加工する際によく見かけるものの、あんまりピン!と来ないものにコンプレッサーがある。音を圧縮する…と言葉では表現できるものの、的確に説明するのは難しい。
そこで今回、自分なりのコンプについての解釈を検証すると共に、その内容をシェア出来ればな…と思う。
コンプレッサーの効果は、その違いを耳で感じられれば説明は不要。が、しかし厄介なことに余程大袈裟に加工しないと、慣れないうちはコンプの効果は感じられない。
よく解らない人にも判る程、加工してしまうとその音は本番には使えない(笑)
だけど一度その効果を理解できると、不思議なものでちょっとしたコンプレッションにあれこれと感想が持てるようになる。
不肖わたくしmog(モグ)程度の輩にも、知らないうちになんとなく判るようになったのよ。
で、今回はその理解を確認してみよう!というわけ。
※前フリが長くなりましたのでコンプネタがお目当ての方は
見出し「実験開始!」まで進んでくださいw
きっかけ
事の発端は、久しぶりにAudacityを触った事。
画像はAudacityプロジェクトへリンク
Audacityというのはオープンソフトとして配布されている音声加工ソフト。タダだから…とはなかなか侮れない機能の充実したソフトウェア。
オープンソフトなど、タダで配布されているソフトウェアについては、そこそこ贔屓のつもりでして、その出処を確かめられるものについては大いに活用すべし!と思っている。
ホント良く出来ているものもあり、なんなら公共機関のパソコンにはLinuxOSを採用すればいいのに…なんて密かに思っていたりして。(課題も多いので大きな声では言いませんw)
閑話休題
話をAudacityに戻しましょうw
久しぶりにAudacityを触ったのは、よく拝聴させて頂いているウェブラジオ・ポッドキャストの加工に使われている事を思い出したから。
Audacityを使っているのに、配布されている音源はどうしてこんなに音量差が激しいの?と思っていた。
サ行やタ行のザラついて聴こえるところ(高音成分)やパ行の吹かれ一歩前の音低音成分)って、どうしても大きい音で録音されがち。音割れさせない為にこうした最大レベルの音に合わせて録音するしかないので、その他の成分は小さいレベルになってしまう。
そんなアンバランスは後々加工の邪魔になるので、歌の収録などではコンプレッサー・リミッターをかけながら録っていたりする。
けど、まぁ音楽を創作・演奏されておられる方々の中にも音声加工の専門知識をしっかり持たれている方は多くないところで、とにかくおしゃべりを聞かせたいんじゃ!!と思い立ってSkype辺りでよく使われるヘッドセットマイクをパソコンに繋いで悪戦苦闘されておられる方に、コンプ云々とは無理な話。
とはいえ、誰かアカの他人様に自分たちの喋りを聞いてくれ!って音声ファイルを公開するのであれば、多少聞きやすく整えるのは礼儀というもの。
とあるウェブラジオ様では会話と会話の無音の部分を取り除き、トークのテンポを整えることにやっきになっておられたことはその会話の中から存じ上げておりましたが、マイクに吐き出した息が吹きかかる「フカレ」という現象はそのままだったり、お話が盛り上がるあまり大きな声になってビリビリに割れてしまっていることに触れないのはちょっと気になっておりました。まぁ、音にちょっと詳しい…って程度で、決してプロフェッショナルなわけではありませんでしたので直接余計なことは言うに至りませんでしたが。それでも最近の音声を確認いたしましたら、おそらくリミッターはかけておられるような痕跡があり、ついにそこまで手が回るようになってこられたんだな…と。お見事です。
とまぁ、そんなこんなで久しぶりにAudacityを触ることになりまして、あれこれいぢっていると「解析メニュー」の中にスペクトラム表示という機能があるの気付きました。この機能、あまり触った記憶がなかったので試しに表示させてみると、ある程度の時間軸の範囲を指定して解析したものが表示される。
つまり、有料のDAWソフトのようにリアルタイムで表示されウニョウニョ動くわけではない。
実験開始!
早速Audacityにサンプル音声を収録。
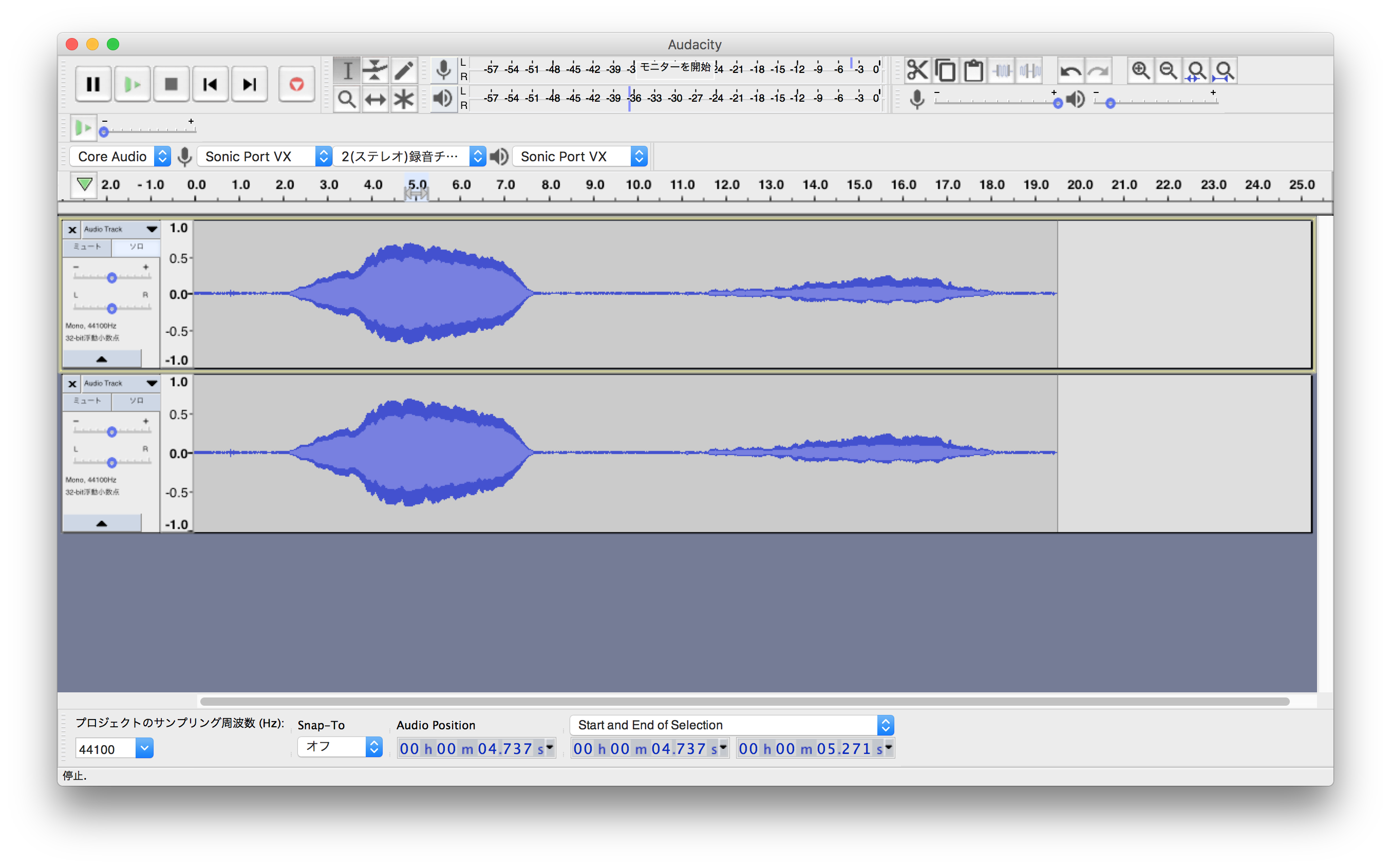
ステレオトラックのように見えますがモノラルで2トラックです。ギターのチューニングに使う440Hzの音叉の音と、その後にわたくしの声で「ラ」の音を「あ〜」と入れてみました。
その後、音叉の音と自分の声を別々にコンプレッサーをかけてみます。
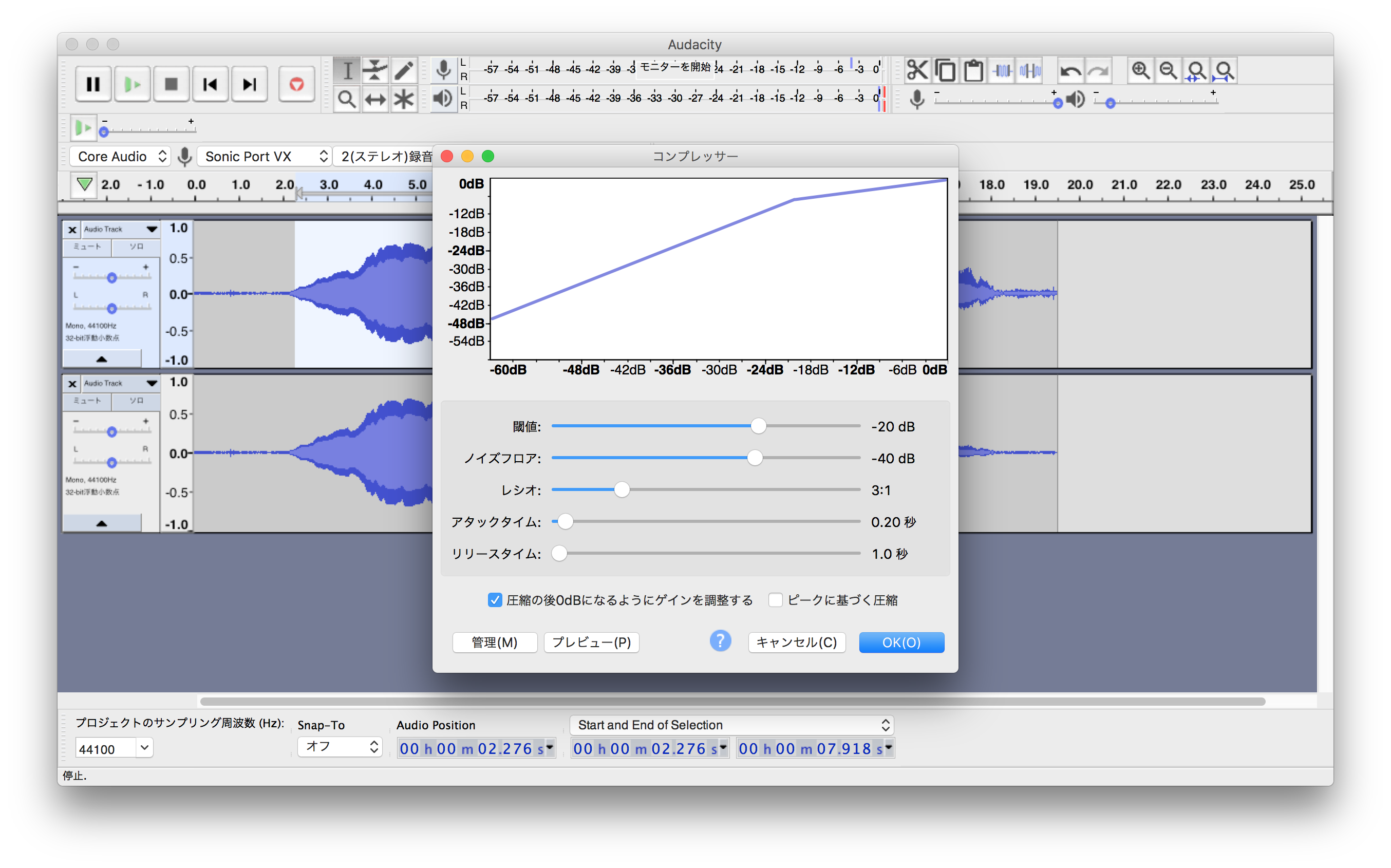
コンプレッサーの設定は以下の通り
閾値(Threshold)
-20dB
ノイズフロア
-40dB
レシオ
3:1
アタックタイム
0,20秒
リリースタイム
1.0秒
それぞれコンプレッサーをかけたことで変化したのが以下の画像。
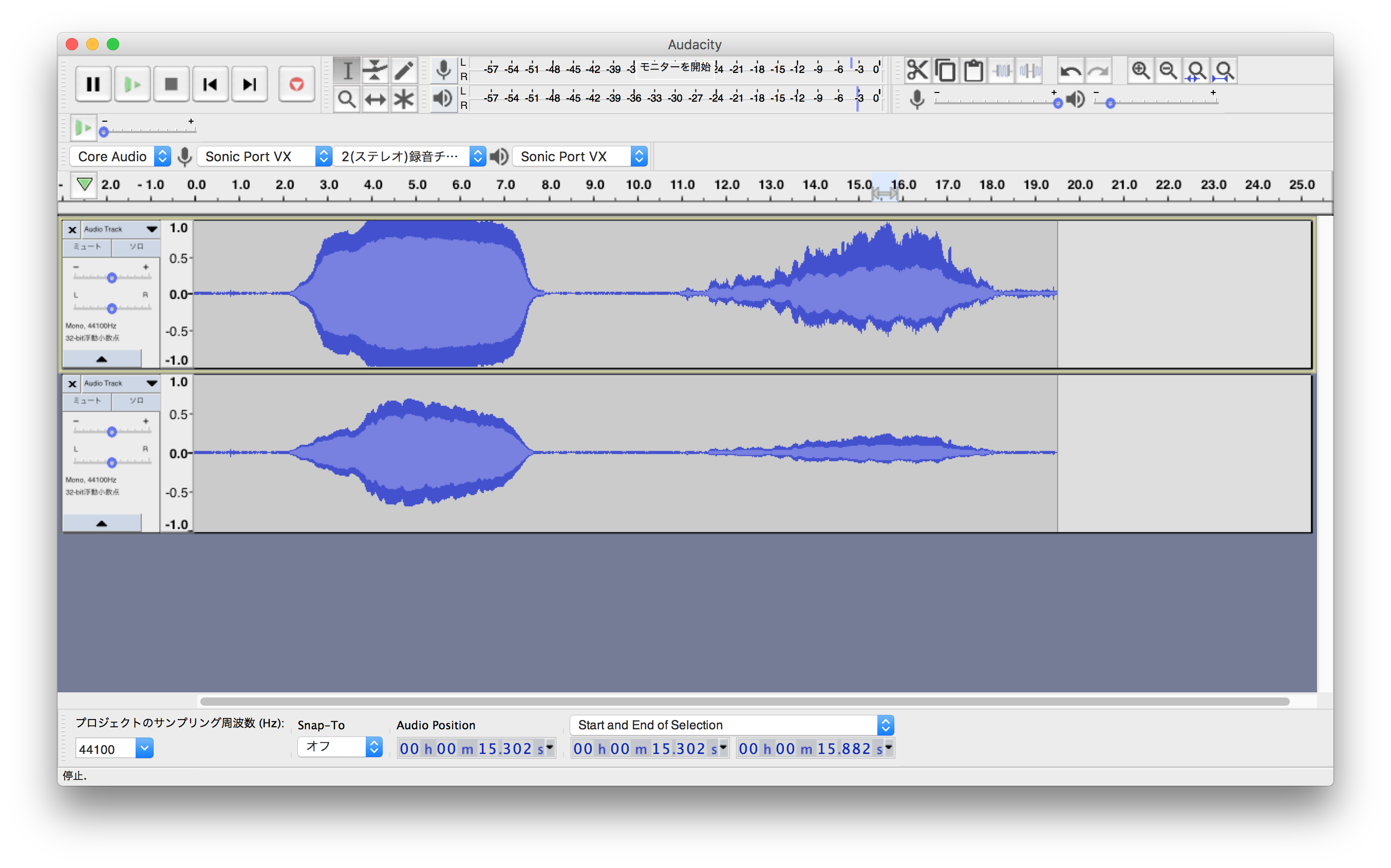
青い波形の上下の幅が広いほど音は大きく再生されます。つまり下の段が元の音声で上の段がコンプ後の音声。
音叉の方(上段左側)は、ちょっとやりすぎちゃいました(笑)設定は同じなんですけどね。
設定画面の「圧縮後0dBになるようにゲインを調整する」にチェックを入れたのがここまで持ち上げてくれたんでしょう。
で、音叉の音から一部を抜き出してスペクトラム表示したものがこちら
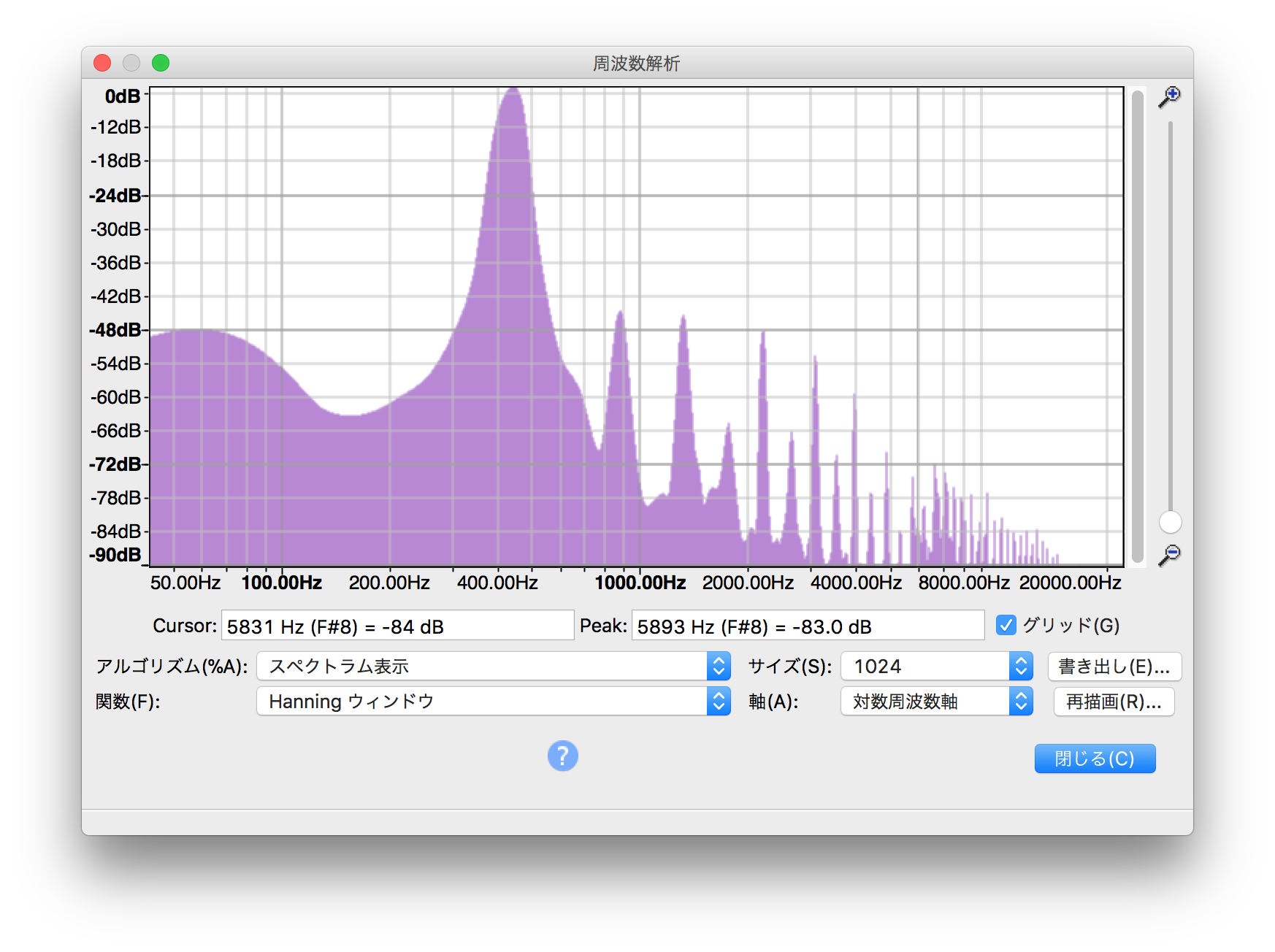
先程の横長の波形が音の大きさを表しながら時間軸に沿って表示されていたのに対し、このスペクトラム表示は横向きの座標に周波数が刻まれていて、縦軸にその帯域に含まれる成分の量…つまりざっくり言えば縦軸が音量。どの周波数がどの程度の割合で発生されているかを見ることが出来るもの。
コンプレッサーをかけた後のものがこちら
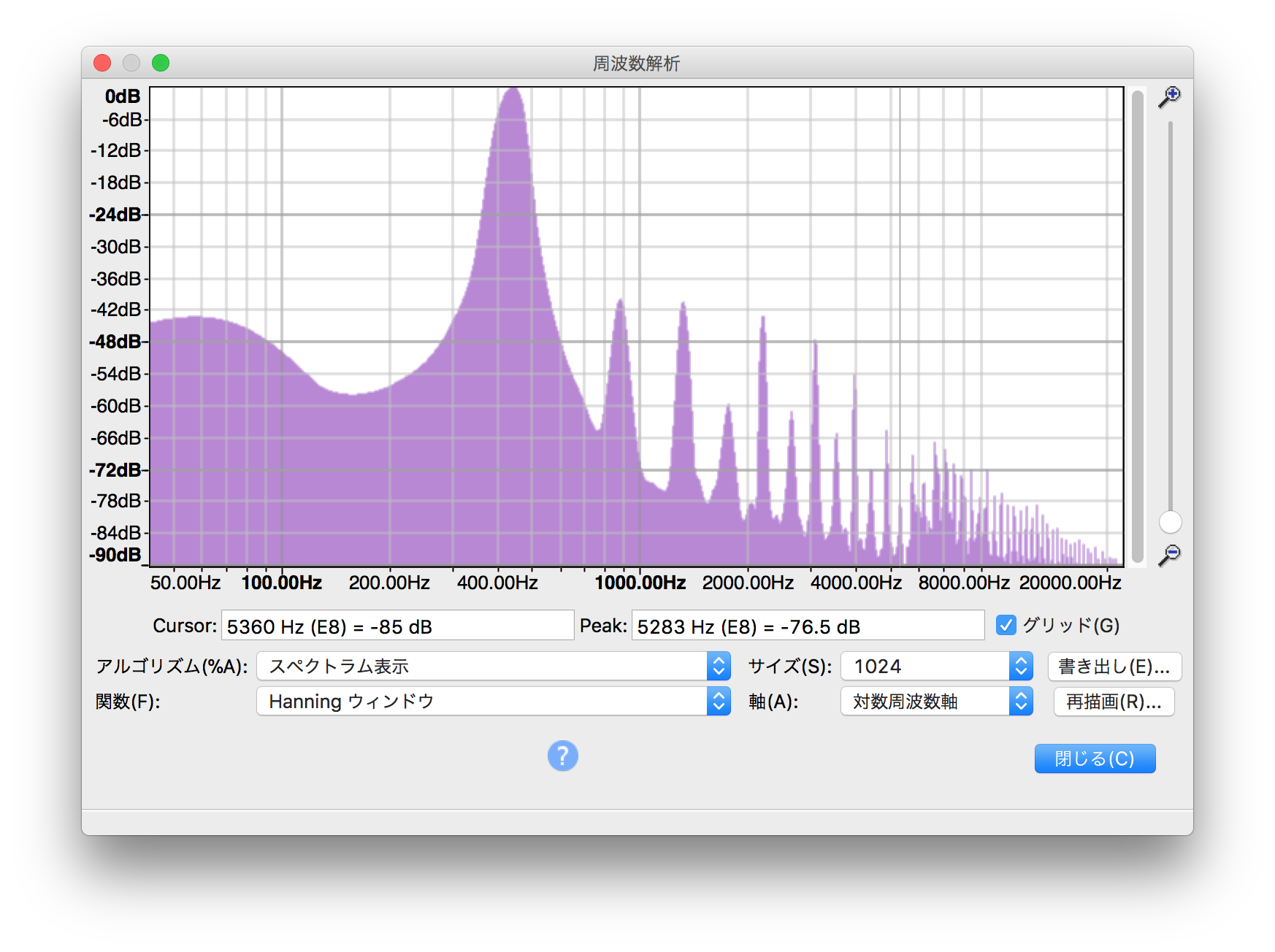
どうも判りづらいですねw
4000Hzから8000Hz辺りの波グラフの谷間に注目していただければ、加工後の方がやや紫の面積が増えているような…
右端の20000Hz辺りを比較していただいても紫の部分が違っているのにお気づきいただけるかと。
周波数別のグラフにしてみるとこの程度の違いでも音声トラックの音量の幅はあんなに違ってくるんですねw
「440Hzの音叉」のスペクトラムだからといって、440Hzにしか音が出ないってわけではなく、倍音成分の880Hz、1760Hz…と様々な周波数が積み重なっています。それでも440Hzの部分が一番大きいことで「ラ」の音と聞き取れるんでしょうね。
続いてわたくしの声の方へ行ってみましょうか。
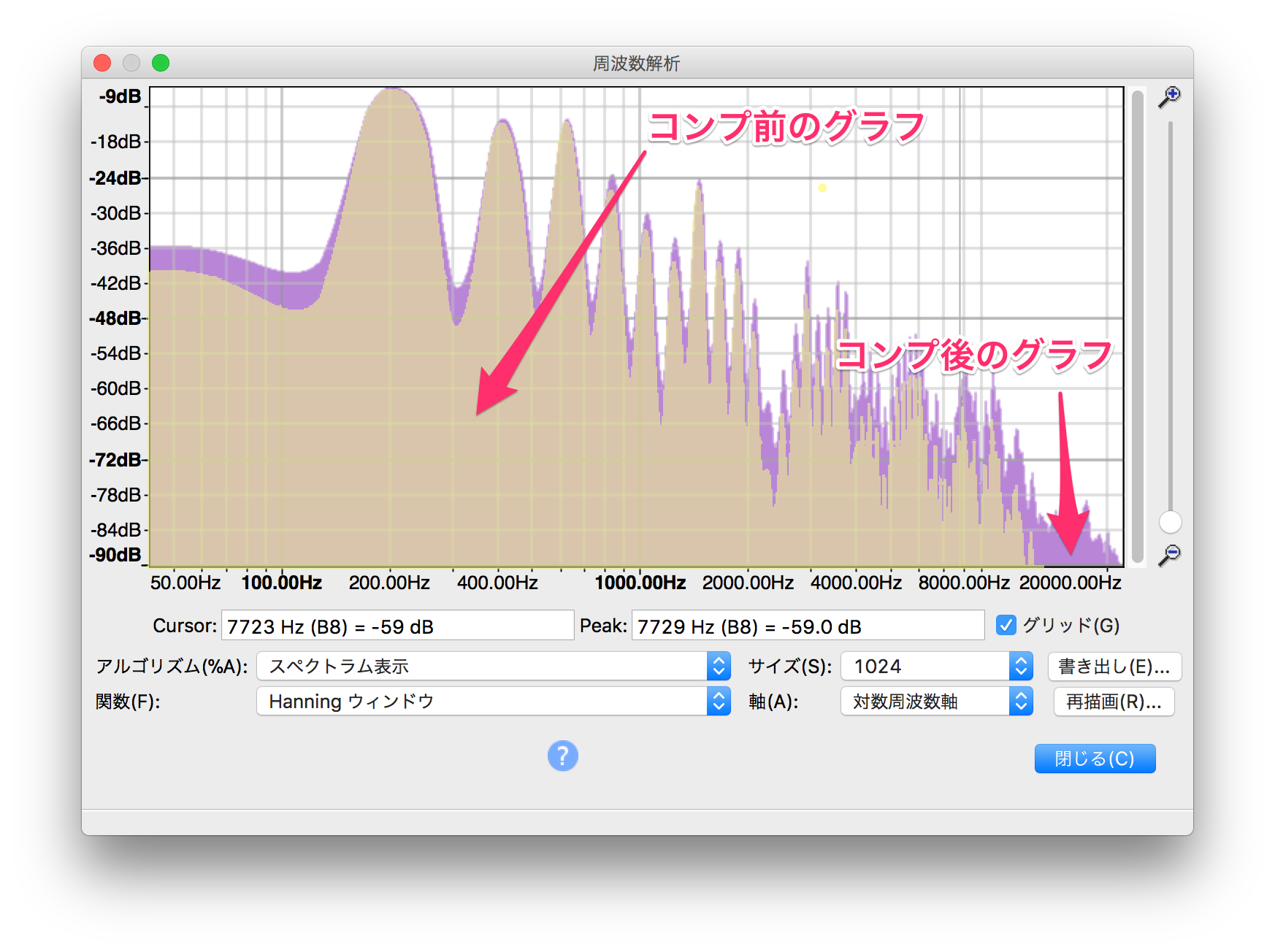
今度は頑張ってグラフを重ねてみましたw
面積の狭い黄色っぽい方がコンプ前…紫のほうがコンプ加工後となります。
こうしてみると、明らかに面積に違いが比較しやすい。
頑張ってよかったw
また、音叉のグラフと比較しましても440Hz、880Hz、1760Hz…など「ラ」の倍音以外の周波数(波グラフの谷の部分が音叉のものと比べて浅いので)がたくさん含まれています。これらの積み重ねが「あ〜」という音声を構成しているんですね。
あとひとつ忘れてはいけないのがわたくしの声がサンプルになっている方のスペクトラム画像には220Hzの波も現れています。これはつまり1オクターブ下の「ラ」と認識されるんやな…と。
まとめ
音叉・音声どちらの場合も、スペクトラム表示をすると波の谷の部分が持ち上げられることで音量を稼げている事が解りいただけたと思います。波の山の部分が必要以上に持ち上がってしまうと、全体の音量が大きくなりすぎて歪の原因となるのは容易に想像できるかと。
コンプレッサーというエフェクターは、指定した音量以上の音は指定した割合で抑えつつ、音量の足りていない部分を持ち上げてくれるもの。耳で聴いただけではなかなか判断出来なかった音量の変化は、今回のように画像として視覚化してやることでイメージしやすくなったのではないでしょうか。
今回の谷の部分が持ち上げられているイメージを頭に描きつつ、ご自分の声を録音してコンプしたものとそうでないものを交互に聴き比べる…などしてみるとよりその違いに気付けますよ。
音が太くなる…って感じはこの事か!なんて。
また、今回のコンプレッサーの効果を周波数別の視覚化によって認識できたことで、耳障りな帯域が持ち上がることも並行して意識できるかと思います。
出過ぎた低音はイコライザーでカットしなくちゃ…とか
サ行の歯擦音(しさつおん)が目立ってしまったのでディエッサーをかまさなきゃ…マルチバンドコンプでもいいのか?…などなど。
こういった気付きにもつながってくれたのだとしたら、今回の視覚による確認も報われるというものです。
今回の周波数帯域別目線によるコンプレッサーの説明って他で見かけたことがないので、なかなかいいお話ができたんとちゃうかな?と思います。
ただし、前フリが長すぎだw
そのうち肝心なところだけ抜き出して、更に良く見かける「音量のヤスリがけ目線」も交えて再投稿せなあきませんね

